



往往做網頁的或是 APP 的頁面都會做成一頁不顯示太多資料,這時 API 有分頁的需求,傳統都會使用 offset limit 來處理,但是這種方式並不適合用於資料量大的資料庫,本篇文章將探討傳統方法的問題以及如何使用 Cursor-based pagination 方式取代。
資料庫 Schema
※ 本篇以 MySQL 5.7 版本做說明
假設現在有個書本管理系統,系統中紀錄了書本的資料,資料包含書名、統一商品編碼以及價格,並且在統一商品編碼以及價格上做了索引。
CREATE TABLE `book` ( `id` INT NOT NULL AUTO_INCREMENT, `name` VARCHAR(200) NOT NULL COMMENT '書名', `isbn` VARCHAR(15) NOT NULL COMMENT '統一商品編碼', `price` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '價格', PRIMARY KEY (`id`), UNIQUE INDEX `__index__isbn` (`isbn` ASC), INDEX `__index__price` (`price` ASC) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
大型資料庫的致命傷
在龐大資料量的資料庫查詢時,有一些查詢方式應該避免,使用者不多的時候使用可能沒有太大影響,但是如果同時許多人使用時,會使的資料庫頻繁處於高負載狀態,如果最後資料庫無法負荷,資料庫可能會倒掉,導致服務無法運作,這邊介紹兩個最常遇到的功能,但是對於大型資料庫應該避免使用的。
致命傷 一、offset limit
最常使用的傳統分頁方案是使用 SQL 查詢使用 offset 與 limit 搭配使用來解決需求。
例如一個分頁有 10 筆資料,而如果要查詢價格小於 100 的並且在第七頁的時候會使用下面的 SQL 查詢:
SELECT * FROM book WHERE price > 100 LIMIT 10 OFFSET 60;
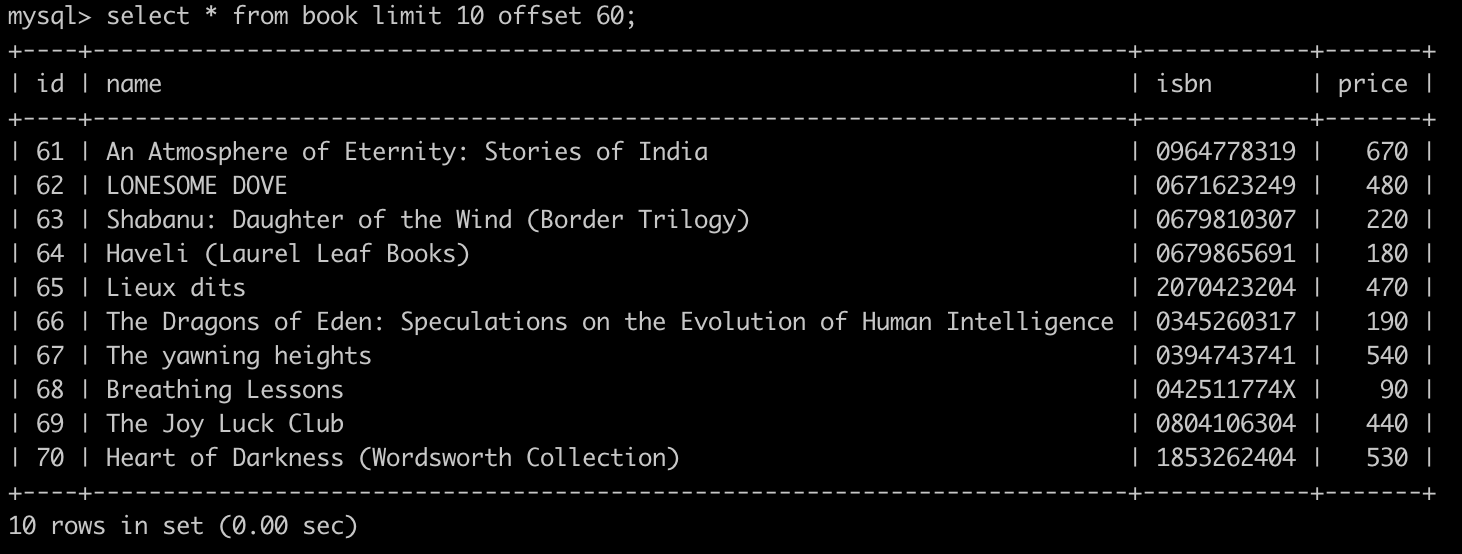
而對於資料庫有稍微深入了解的話,就會知道 offset 在運作的時候需要從頭開始尋訪 (Scan table) 才能知道要取哪一段資料,所以當分頁越後面的時候查詢時間就會越久,在小型資料庫並不會有特別的感覺,但是當資料量非常龐大 (到達幾千萬或是上億時) 時,就能感受到時間明顯的差距。
例如下面有人直接跳到 300001 頁的時候,所花費的時間就明顯上升了不少:
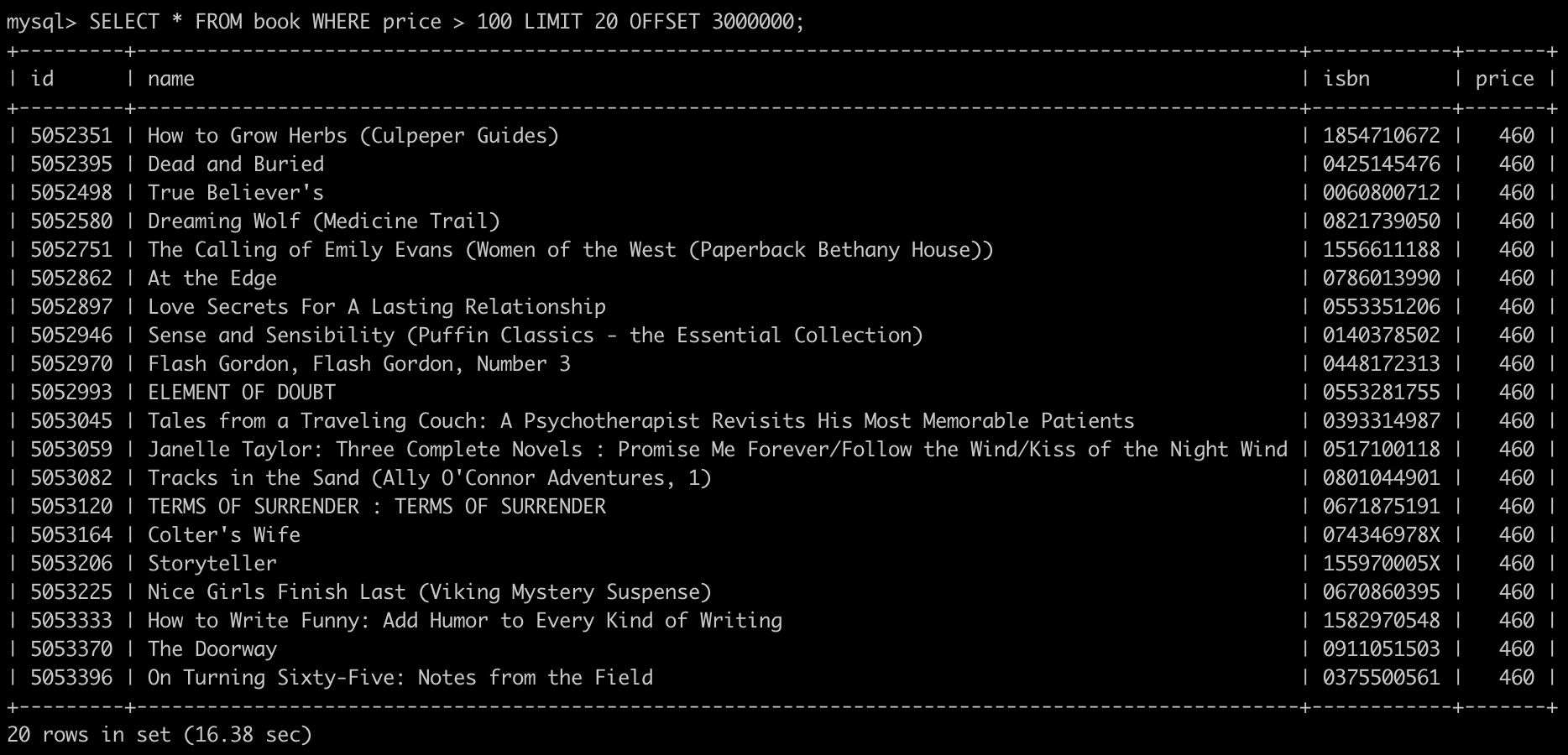
致命傷 二、總頁數

另外一個對於龐大資料量的資料庫傷害蠻大的是總頁數,要知道符合條件總數量,資料庫系統必須尋訪過每個符合條件的節點才能夠算出總數量。
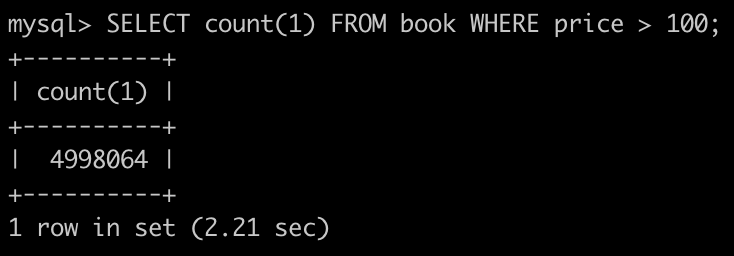
如果再搭配上面 offset limit,往往在顯示一個頁面的時候,會使用兩個非常消耗資料庫效能的 SQL,當使用者一多的時候資料庫可能會處理不來導致網站倒掉。
這時就會需要想一下資料量龐大時總頁數跟總數量真的是必要的嗎?如果是必要的話資料是否一定要很精準,並且可否使用其他代替資料庫?
替代 offset limit 的方案 – Cursor-based pagination
對於大型資料庫做分頁的其中一個替代方案便是 Cursor-based pagination,其能夠有效使用資料庫的 index 進行尋訪,不會對於資料庫造成傷害。
其運作方式是將有 index 的欄位的值記錄下來,丟給 Client,而 Client 如果如果要查詢下一頁時欄位丟給 API,API 再以後續欄位進行查詢。
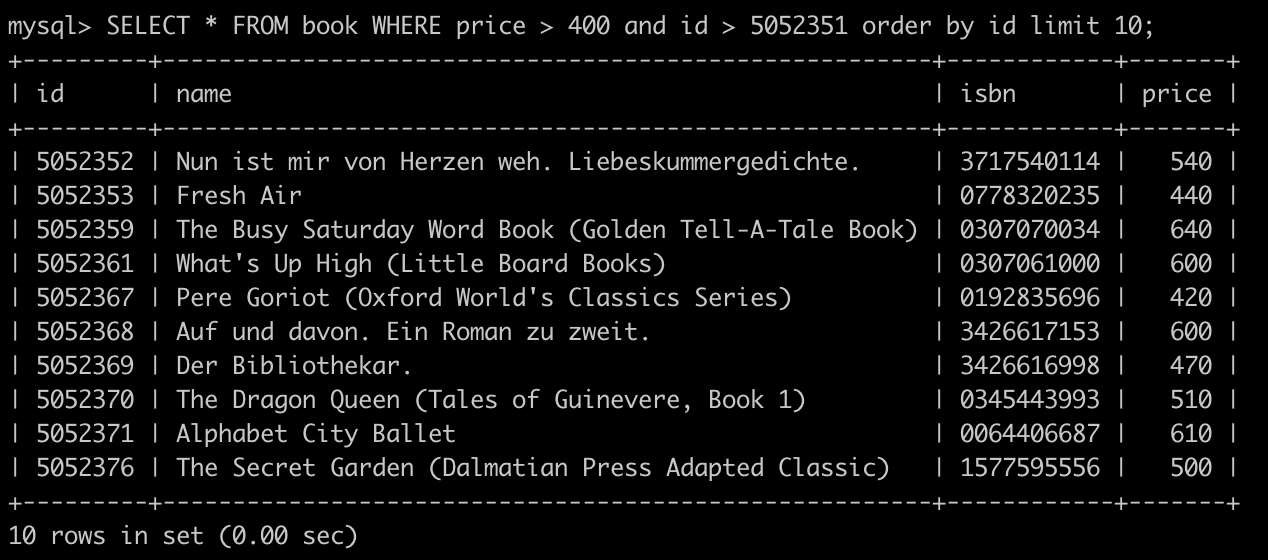
直接以 SQL 進行說明,假如我們要查詢第一頁大於 400 塊的書會輸入以下的 SQL:
SELECT * FROM book WHERE price > 400 limit 10 order by id;
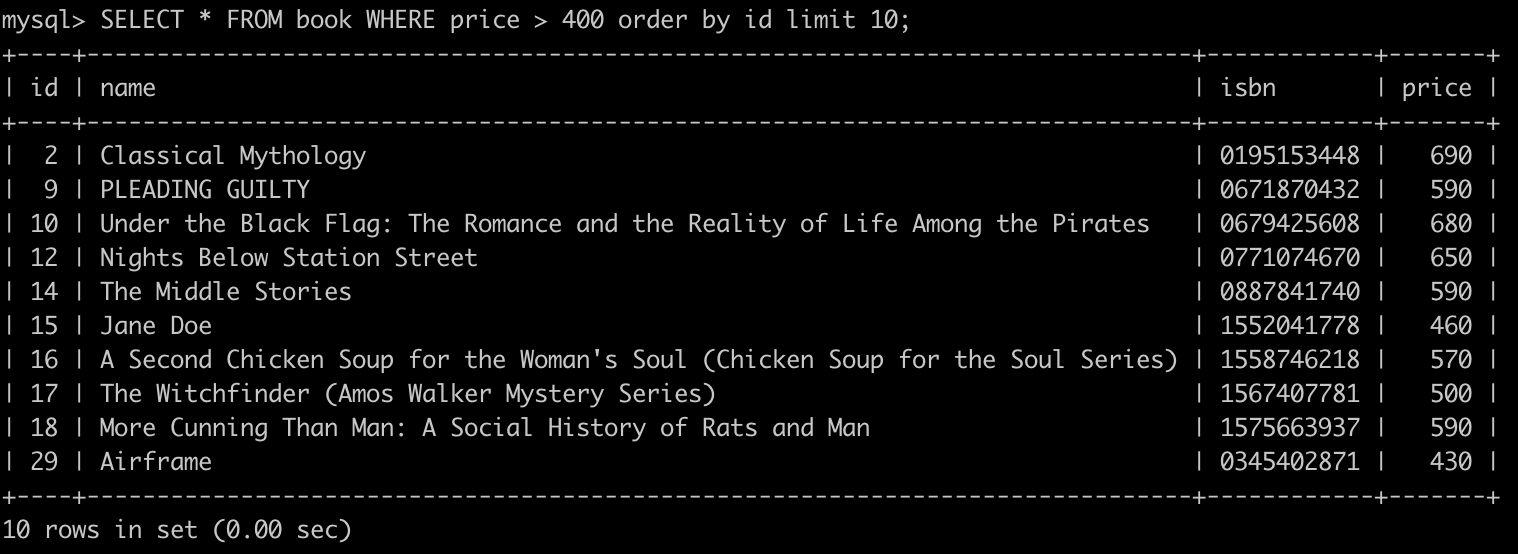
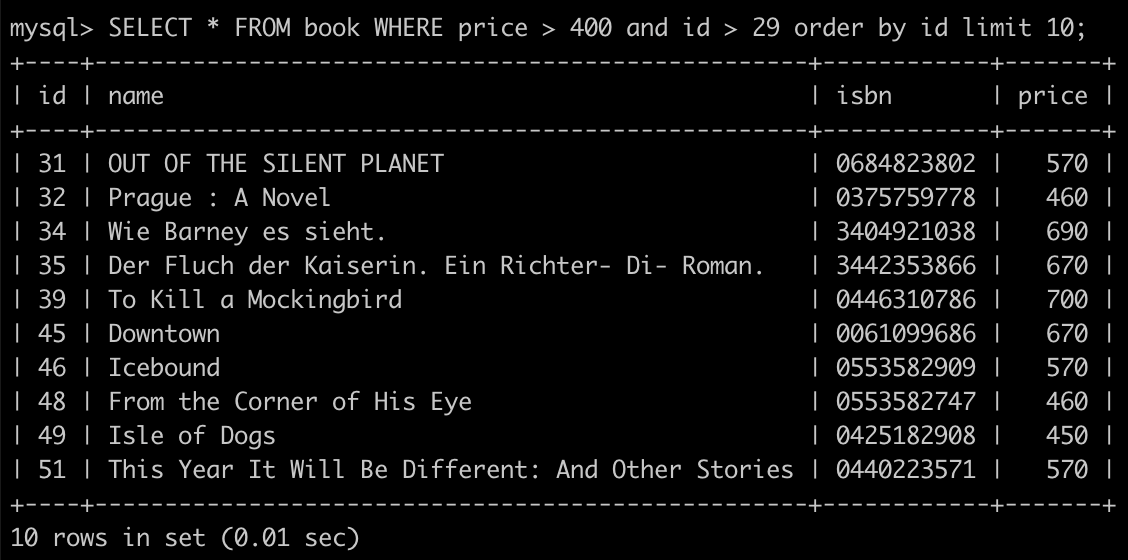
這時可看到最後一個 id 是 29,只需要將 29 的值丟給 Client,而 Client 要查詢下一頁的資料只需要將這個 29 丟給 API 就再以 30 開始進行查詢
SELECT * FROM book WHERE price > 400 and id > 29 order by id limit 10;
即使使用者一直按下一頁到達了很後面的頁數也不會對資料庫有大的傷害
實際實作
Page Token 介紹
在實作時可以在丟給前端的資料動手腳,不是把單一 id 丟給 Client,而是另外使用一種實現方式:pageToken。
pageToken 是用來跟 API 請求資料使用的 token,裡面會存放一些後端才會用到的資料,對於前端來說就只是一個單純的字串而已,而對後端的好處是:封裝性,一般會是將資料進行加密來達成,對於前端單純就是一串字串,而如果哪一天可能因為後端架構改變,而需要改變 token 內容時對前端並不會有任何影響,這邊使用 pageToken 內存放資料查詢的分界點。
單純查詢實例
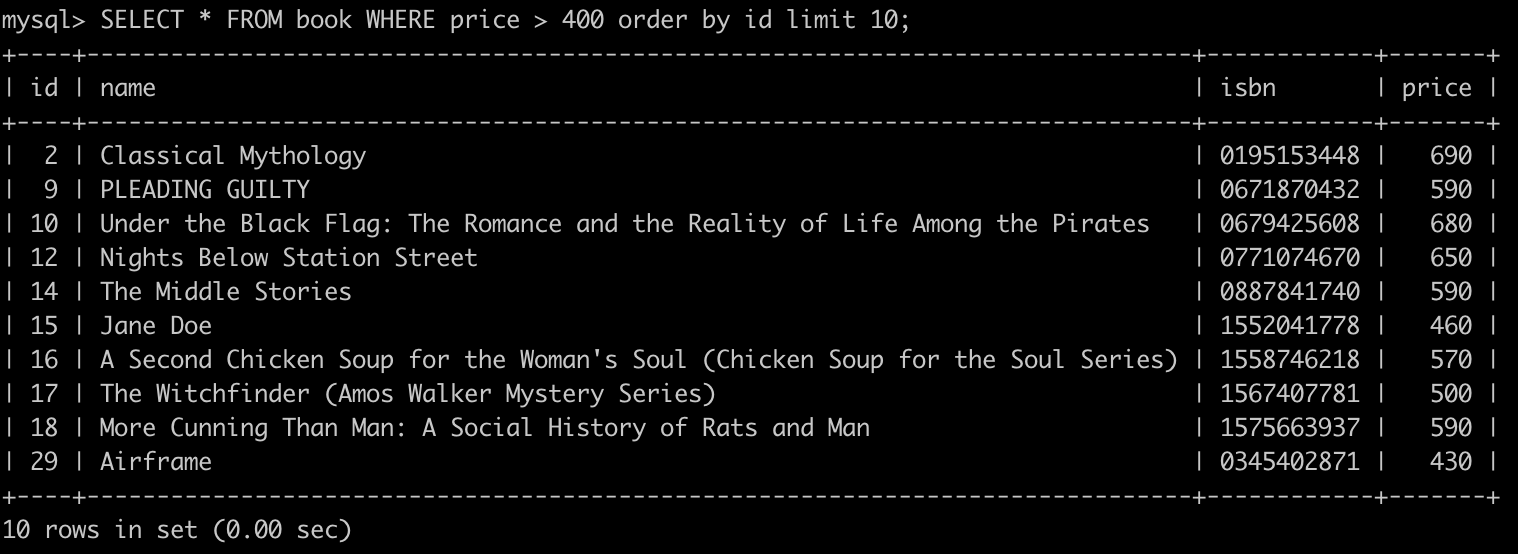
我們以前面第一頁的 pageToken 來做示範,首先我們以下面的 SQL 查到第一頁的的資料以及最大的 id 是 29
SELECT * FROM book WHERE price > 400 limit 10 order by id;
這時候 API 丟給前端的 pageToken 中就可以包含 id 29 這個資料 (這邊 token 內容以 json 格式當作範例,為了方便解說所以使用 base64 方式做加密,實際實作可以用其他演算法如 DES、AES 這種需要 key 才能解密的演算法才更安全)
token 內容是 {"id": 29},經過 base64 過後資料為 eyJpZCI6IDI5fQ==,這個字串就是查詢下一頁的 pageToken
API 便能回應以下的資料:
{
"data": [...],
"previousPageToken": null,
"nextPageToken": "eyJpZCI6IDI5fQ=="
}
而當客戶端丟出 /api/books?nextPageToken=eyJpZCI6IDI5fQ==,API 解開後得到 id 是 29,便可知道要查詢大於 29 的資料
SELECT * FROM book WHERE price > 400 and id > 29 order by id limit 10;
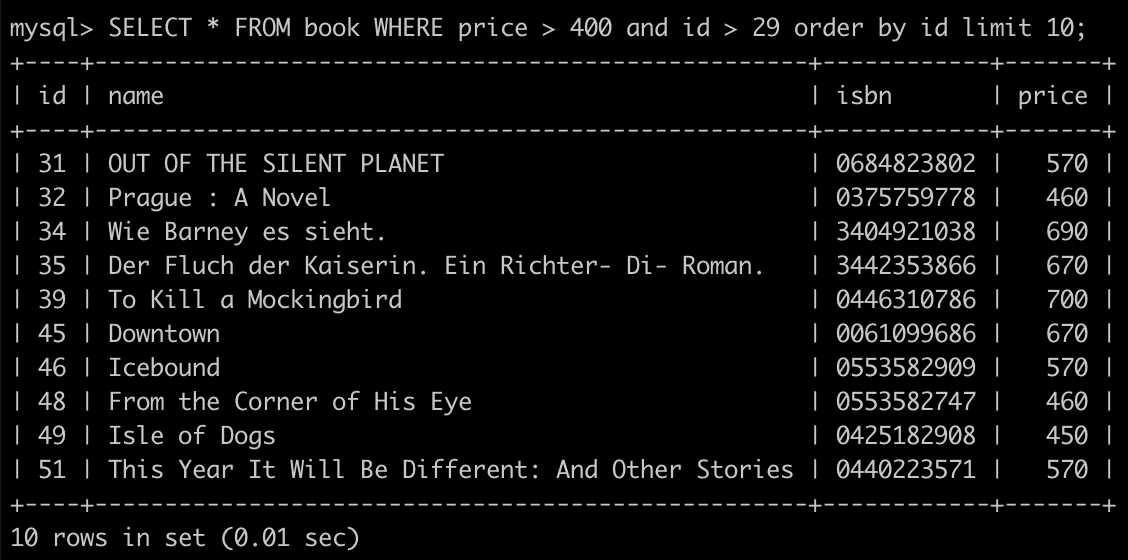
這時產生下一頁的 pageToken 資料 {"id": 51},過 base64 後為 eyJpZCI6IDUxfQ== 為,而查詢的 pageToken 就能夠當作 previousPageToken
API 就能夠回應:
{
"data": [...],
"previousPageToken": "eyJpZCI6IDI5fQ==",
"nextPageToken": "eyJpZCI6IDUxfQ=="
}
含有排序查詢實例
前面的查詢並不含排序,這邊介紹如果有排序的話可以如何實作,假設現在需求是需要價格從低到高進行排序。
剛剛的範例中我們,只有一個欄位 id,因為值是絕對唯一的,很適合做分界面,可是假如只使用 price 做排序時,分界點就比較難以區分因為 price 很有機率重複,所以這邊有個技巧就是把 id 加入組成絕對不會的組合來做分界點。
其中因為是由價格低到高排序,所以 price 當做高位數 (排序優先權高),id 當做低位數,這樣就能組成絕對不會重複的分界點,並且達成類似於下圖的排列方式。
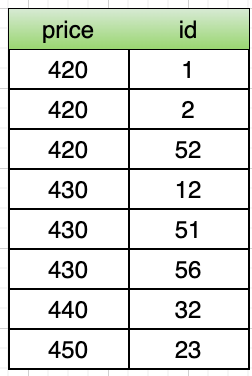
這邊以 price 這欄位進行排序做示範,查詢第一頁的 SQL 如下:
SELECT * FROM book WHERE price > 400 order by price, id limit 10;
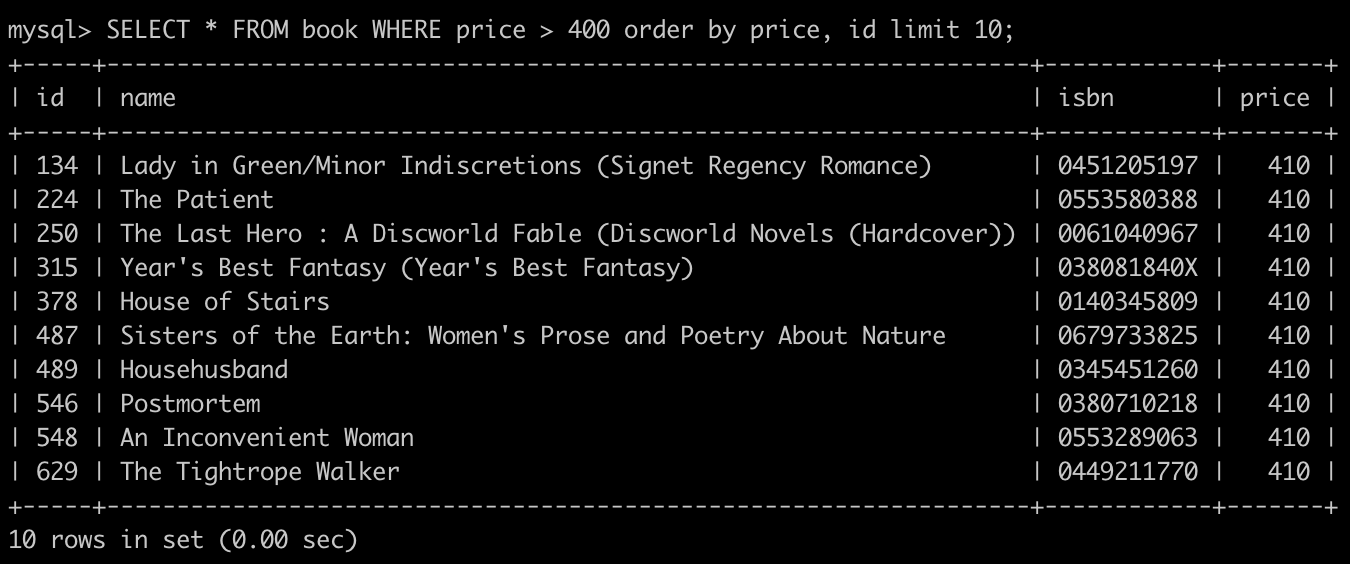
取得的 id 最大 629 ,price 最大是 410, 將這兩個值組成 {"id": 629, "price": 410},經過 base64 加密後取得 pageToken 便是 eyJpZCI6IDYyOSwgInByaWNlIjogNDEwfQ==
API 就能夠回應:
{
"data": [...],
"previousPageToken": null,
"nextPageToken": "eyJpZCI6IDYyOSwgInByaWNlIjogNDEwfQ=="
}
而 client 在查詢下一頁時,/api/books?nextPageToken=eyJpZCI6IDYyOSwgInByaWNlIjogNDEwfQ==,便能取得分界點是 {"id": 629, "price": 410},使用下面的 SQL 查詢下一頁:
SELECT * FROM book WHERE (price = 410 AND id > 629) OR (price > 410) order by price, id limit 10;
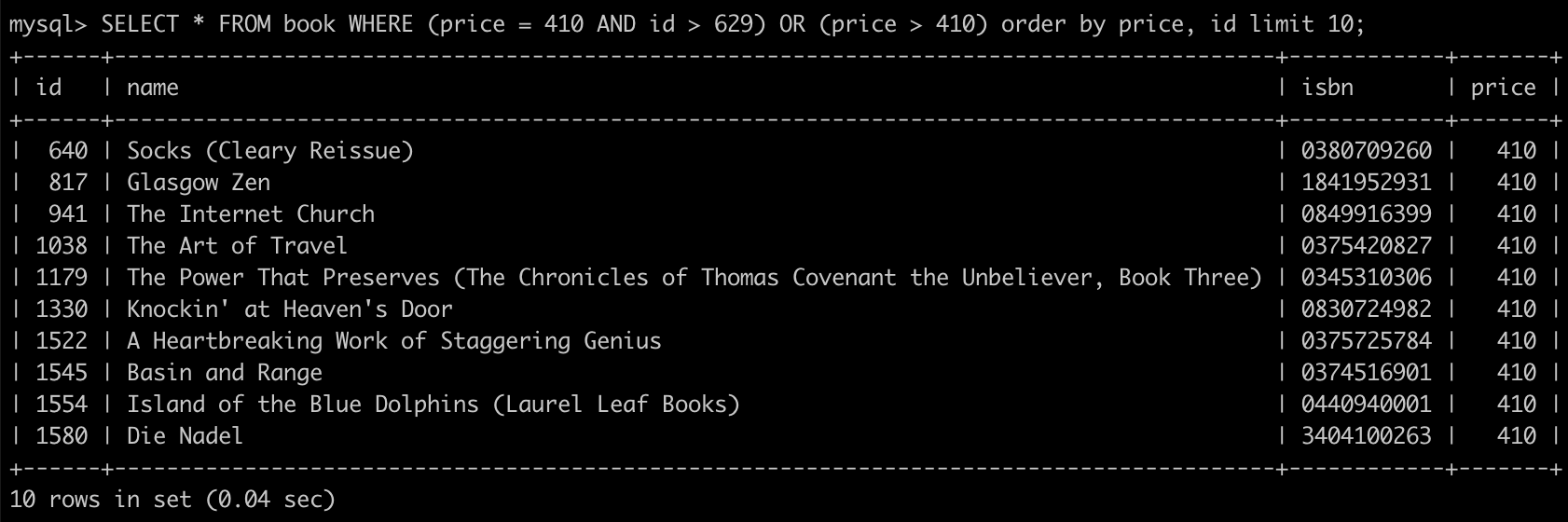
而 previousPageToken 部分運作方式則與前面方式相同