



前一篇已講解如何設計 index,本篇將介紹如何知道目前使用的 SQL 用到了哪個 index 以及在有 index 的情況下如何使用有效使用 index。
範例 schema
這邊使用一個範例是電商的商品,資料庫存了商品的名稱、條碼種類、條碼值以及價格,並且有兩個 index 分別用來查詢條碼以及價格。
CREATE TABLE `item` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) NOT NULL COMMENT '商品名稱', `code_type` varchar(5) NOT NULL COMMENT '條碼種類', `code_value` varchar(20) NOT NULL COMMENT '條碼數值', `price` varchar(45) NOT NULL COMMENT '價格', PRIMARY KEY (`id`), KEY `__code_type__code_value__index` (`code_type`,`code_value`), KEY `__price` (`price`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
MySQL 如何知道 Query 的 SQL 使用了哪個 index
假設我們進行複雜 SQL 查詢時,不確定會不會使用 index 的時候,或是想知道是使用哪一組 index 時,可以在輸入的 SQL 前面加上 desc 進行查詢,便會顯示查詢可能會使用的 index

以上這個 SQL 顯示 possible_keys 是 null,表示查詢並沒有使用 index , rows 表示會需要檢索過多少筆才能找到資料。

而上面這個 SQL 則顯示會使用 __code_type__code_value__index 這個 index 來進行查詢,而 rows 為 1 只需檢索一筆資料就能找到結果。
※ 對於資料庫效能考量,rows 這個值是越小越好,表示經過 index 濾出後不需要對太多筆資料進行值的比對。
有效使用 index
原本的情境是假設查詢 code_value 時一定會給對應的 code_type 一起查詢,但是假如今天遇到一個臨時狀況是有人只有提供條碼為 7977761108033,但是 code_type 已經遺失了不確定是什麼,那這種時候要如何處理呢?
直覺可能會直接使用一個 SQL 查詢:
select * from item where code_value = '7977761108033';
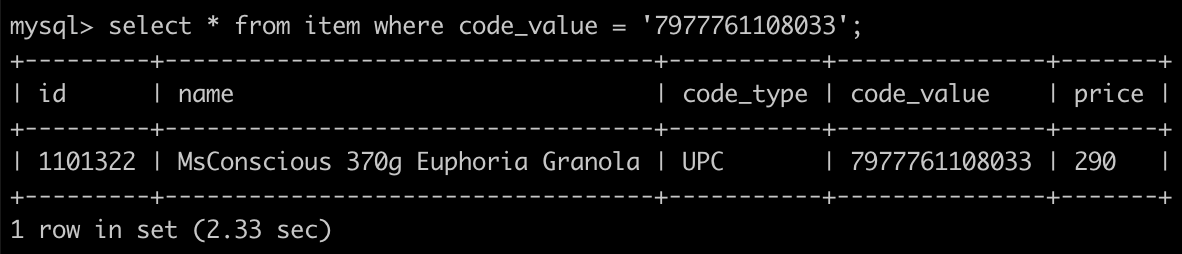
這邊在一個資料筆數 500 多萬筆可以看到查詢時間花費了 2.33 秒,是因為沒有使用到 index,可能不會覺得太久,但是如果資料量到達上億的時候,這時間可能就會超過幾分鐘了,且不會因為這個臨時需求增加 index,因為對於資料量達上億筆的 table alter 可能需要執行好幾個小時,所需要的成本太高了。
那這邊要怎樣解決這個問題呢?
我們可以先窮舉出所有 code_type 後,再搭配一起查詢 code_value 這樣就能使用到 index。
select distinct code_type from item;
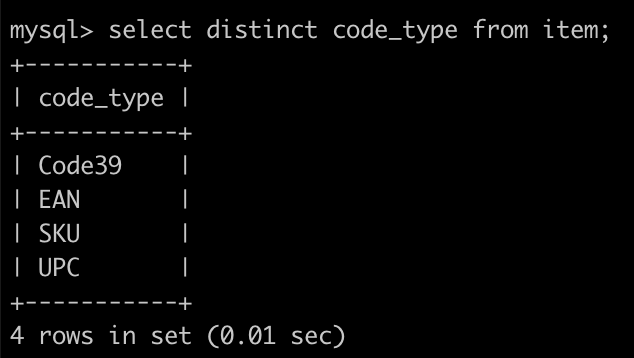
因為有 __code_type__code_value__index 這個 index 的關係,在進行窮舉的時候速度非常快,接著可以將所有的 type 使用 where in 方式搭配進去查詢
select * from item where code_value = '7977761108033' and code_type in ('Code39', 'EAN', 'SKU', 'UPC');
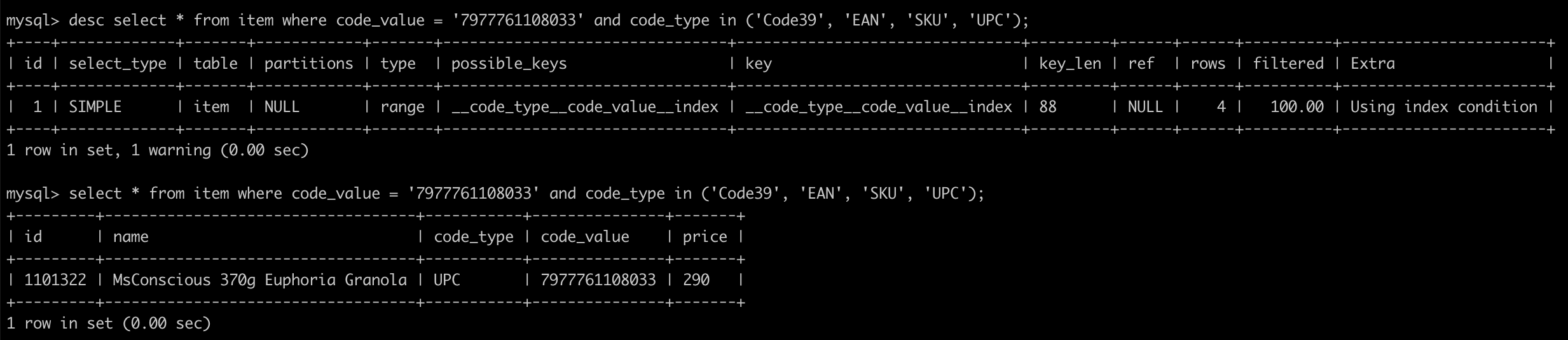
由這邊可以看出,雖然我們多使用了一個 SQL 來查詢,但是整體時間卻大幅度的提升了。